Ujjwal Sharma
Business Analytics | Data Analytics | Data Science | Machine Learning
📄 Download ResumeBusiness Analytics | Data Analytics | Data Science | Machine Learning
📄 Download ResumeI am a graduate student in the M.S. Business Analytics program at California State University, Sacramento, with a passion for data-driven decision-making, process improvement, and strategic communication. As the current President of the MSBA Association (MSBAA), I lead student engagement efforts and foster connections between academia and industry through events, mentorship, and collaboration. Professionally, I serve as a Graduate Intern at Sacramento State and have previously worked as a Program Analyst and Program Coordinator. My experience includes building interactive dashboards, conducting advanced data analysis, and developing machine learning models to uncover trends and support business outcomes. I’m proficient in tools and languages including SQL, Tableau, Power BI, Python, and Excel, and I thrive in environments where analytical thinking meets real-world application. I’m driven by the challenge of turning complex data into clear, actionable insights. With a background that blends technical skills and leadership, I aim to support organizations in making smarter, evidence-based decisions that create long-term value.
Facilitated multi-department coordination through Scrum methodology and Gantt charts. Designed a shared Excel template for customer data tracking and created tutorial content to support users.
Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn, PyTorch, TensorFlow, Predictive Analytics, XGBoost
PostgreSQL, SQL, DBMS, Data Warehouse, Star Schema, Relational Databases, ETL pipelines
EDA, Regression, Hypothesis Testing, Statistical Modeling
GCP (BigQuery, DataFlow, Pub/Sub, Cloud Data Fusion, Firebase), AWS (RedShift, S3, Lake Formation)
Microsoft Excel, Microsoft Office, GitHub Actions, CI/CD, Automation, Agile, ServiceNow, Power Automate, Tableau, PowerBI
Nov 2025 – Nov 2025
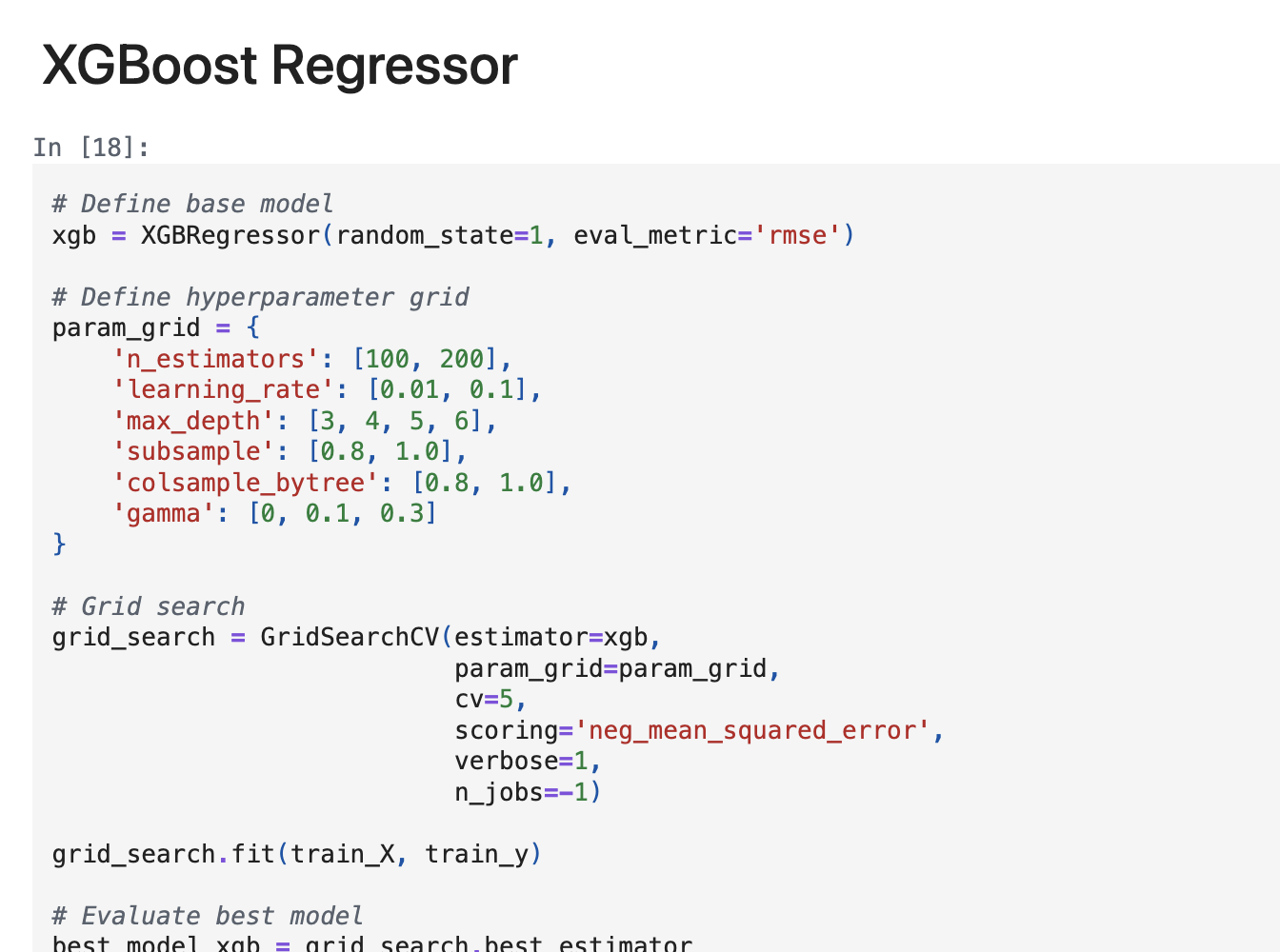
Built an ensemble regression pipeline to predict Spotify track popularity (0–100) from audio features (acousticness, danceability, energy, loudness, etc.) plus engineered signals like dance_energy and key one-hot. Used hold-out validation (random_state=1) and compared Bagging, Random Forest, and XGBoost with MSE/RMSE/MAE/R² and permutation importance. Chose XGBoost because it achieved the best validation (MSE ≈ 92.19, R² ≈ 0.8065) while training in minutes versus >40 minutes for the others. Its built-in regularization (learning rate, depth, subsampling, L1/L2) yielded better generalization and stable performance, making XGBoost the most practical, accuracy-per-minute winner for deployment.
Aug 2025
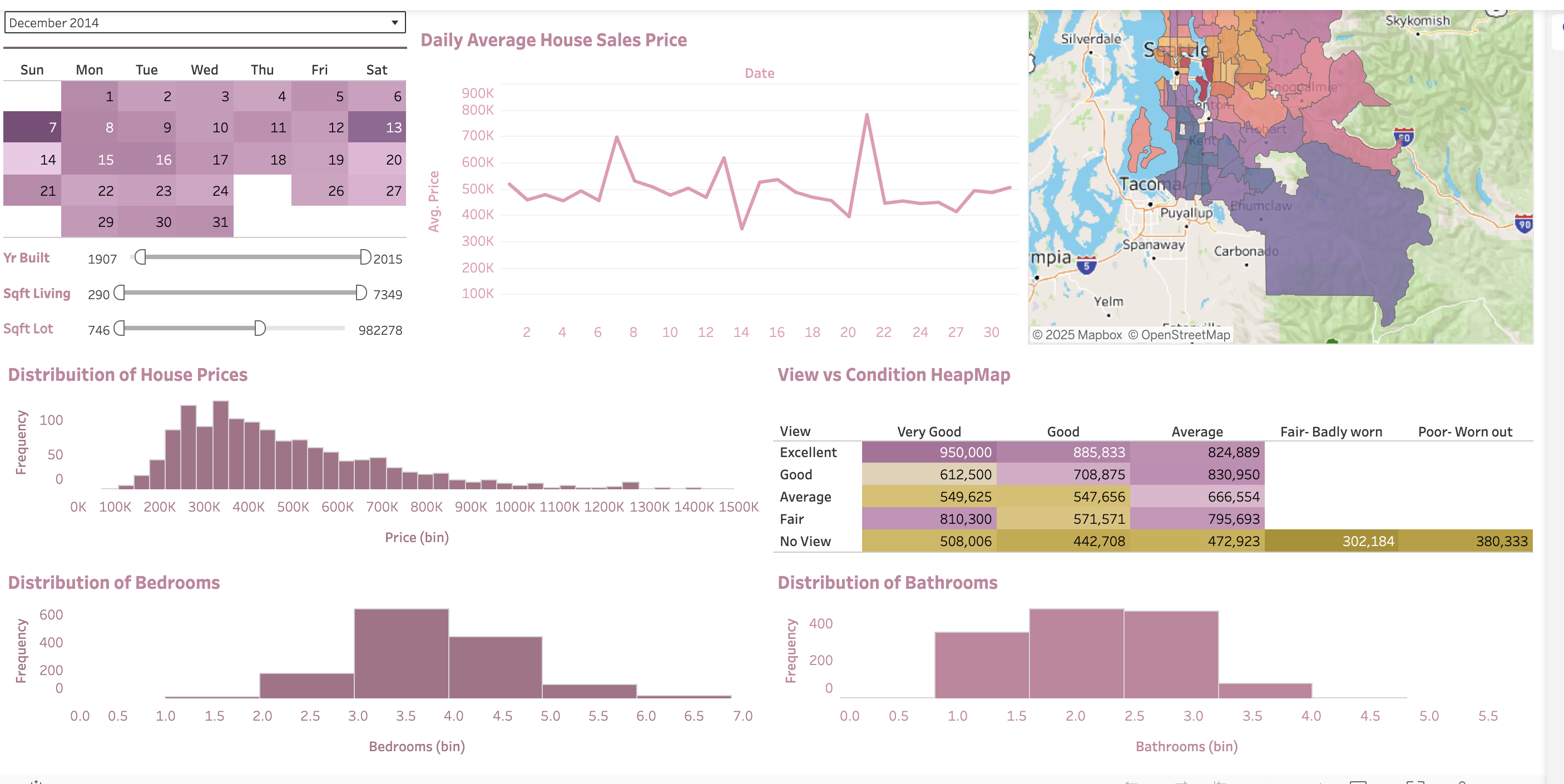
April 2025 – May 2025
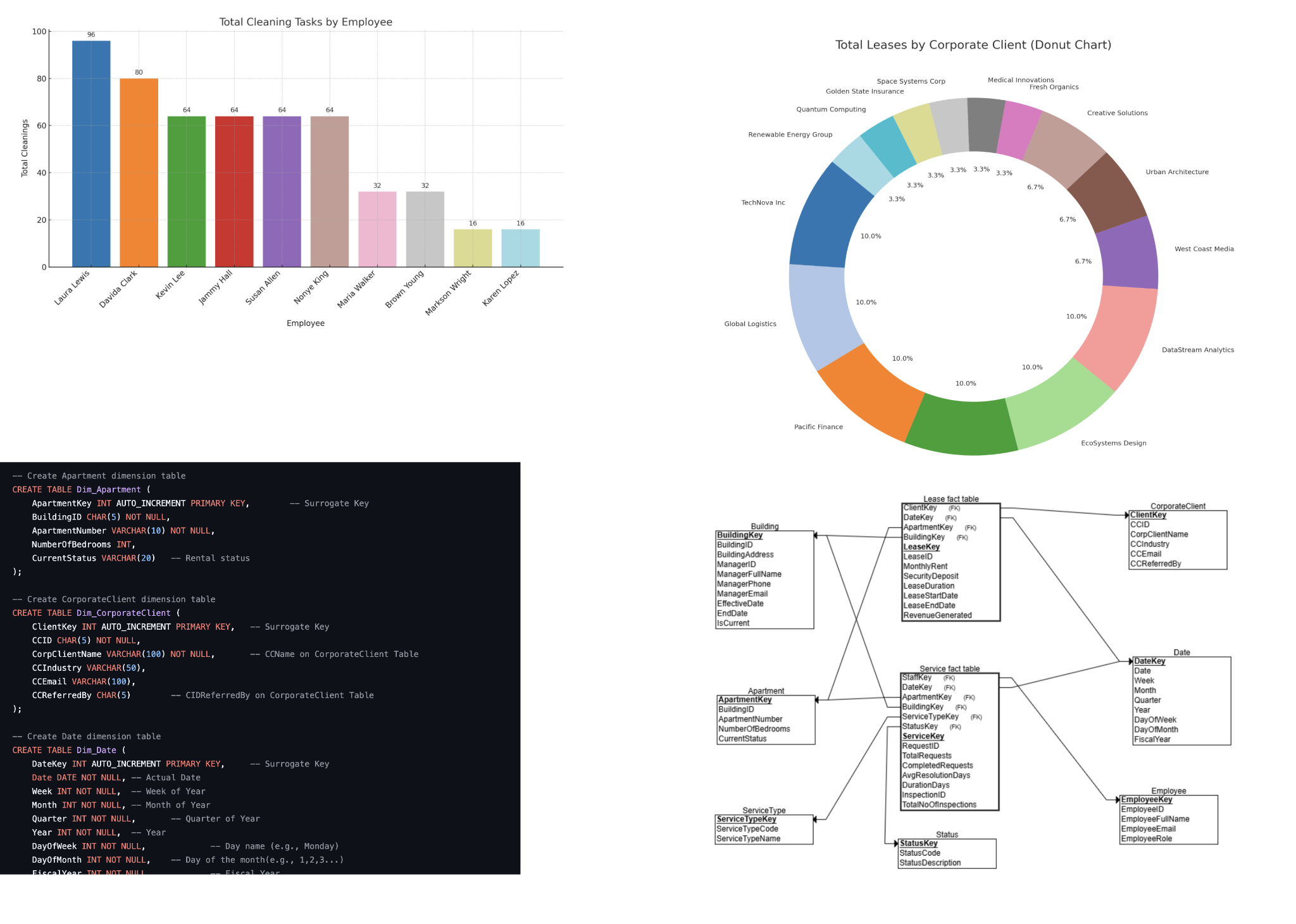
June 2025 – June 2025
Built an end-to-end ML pipeline in Python: handled skew (Yeo–Johnson), scaled & reduced dimensions (PCA), and compared 3 classifiers ( SVM, RandomForest, Logistic Regression). I also utilized joblib to export the models. Ran 5-fold CV: – Logistic Regression: 86.0% – Random Forest (100 trees): 91.5% – SVM (RBF kernel): 91.5%
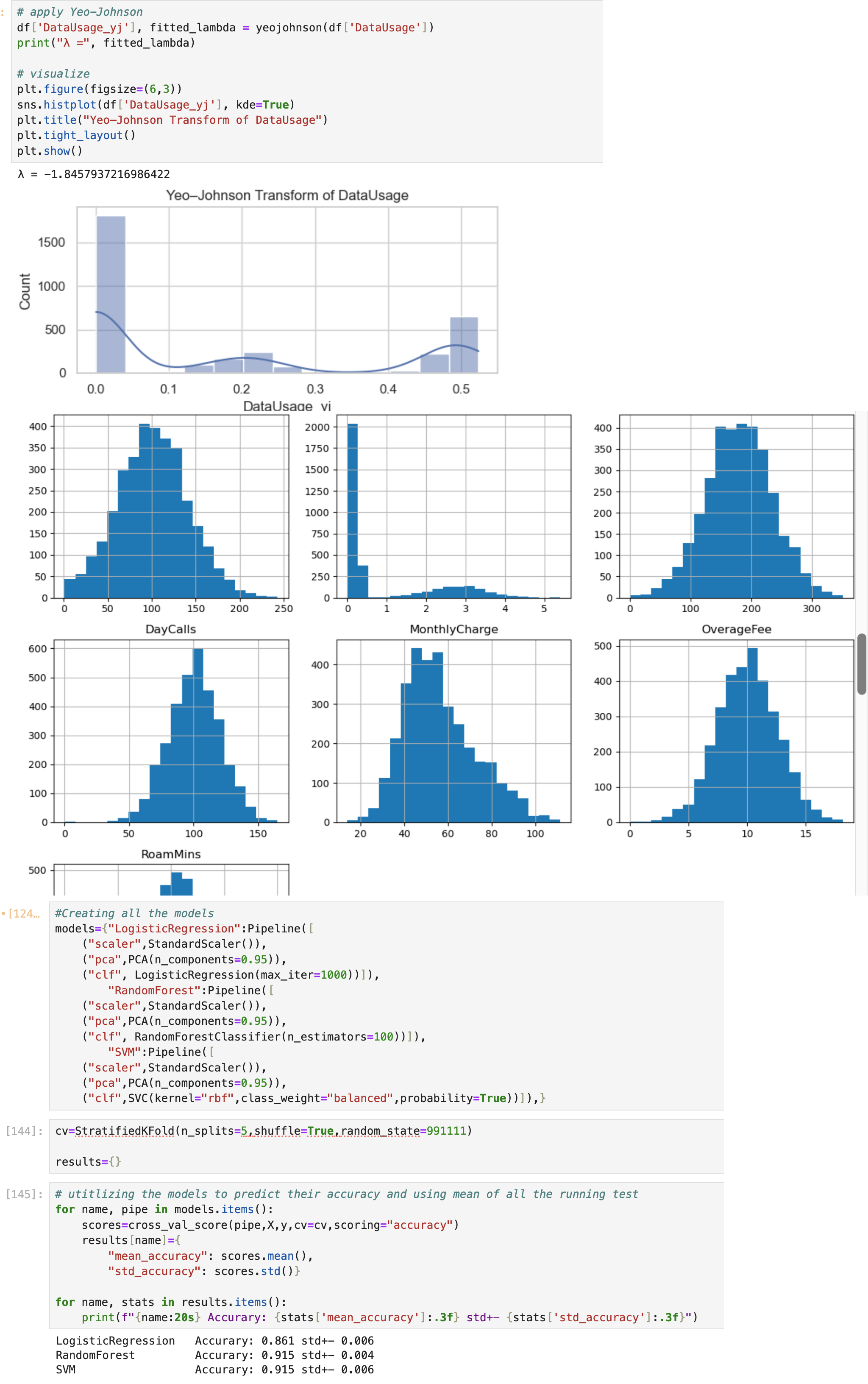


EDA, hypothesis testing, sampling using pandas, seaborn, matplotlib, numpy, scipy.stats.
